Eigen Artificial Neural Networks, a Novel Way to Optimize Neural Networks using Quantum Mechanics

Markus Winkler - https://www.pexels.com/photo/conceptual-quantum-word-with-wooden-blocks-30901565/
Table of Contents
Introduction
An Eigen Artificial Neural Network (EANN) is an optimization method for neural networks based on the laws of quantum mechanics, developed by I-CON since 2019. Although initially designed and focused on neural networks, it is also applicable to learning systems in general.
The name (eigen) derives from the mathematical nature of the algorithm, which uses eigen-equations. Associated with these, we have eigenfunctions and eigenvalues. These types of equations are widely used in mathematical physics and engineering and form the structural basis of quantum mechanics.
To simplify the discussion, we will consider only the application to neural networks.
Deterministic Algorithms
Looking back at the development of science since Galileo, we can observe the way many problems in the natural sciences have been approached and solved. These methods of analysis have certain elements in common, which lead to the development of a mathematical model (at least in the exact sciences) that allows predictions to be made.
What does “predictions to be made” mean? It means obtaining the numerical value of certain difficult-to-measure quantities from easier-to-measure quantities.
It means nothing more than that.
Now, from this premise, which also acts as a definition, it is implicit that given a quantity about which we want to make predictions (the difficult one), we must be able to identify all the easy quantities on which it depends with absolute certainty. Otherwise, we cannot make predictions. So, our quantity to be predicted is a mathematical function of a certain number of independent variables (the easy ones), which we have completely identified (i.e., all of them) in some way, for example, by conducting experiments or by a theoretical approach.
What we simply want is a formula that allows us to calculate what we need based on known facts.
Let’s take an example. Imagine we have two groups of oppositely charged particles at a certain distance. Imagine we have a device that allows calculating the attractive force between these groups of particles, but building it is difficult, and measuring it is cumbersome. This “force” is a concept that has been understood to be relevant to our business and proposed theoretically in a way that doesn’t interest us. However, we can easily measure the charges and the distance between them.
We do some experiments. We see that if we add or remove some charges, the force increases or decreases. We also see that if we increase the distance, the force decreases. From this, we deduce that there is a law that will be a quotient of at least two quantities. In the numerator will be some function of the number of charges, while in the denominator will be some function of distance, which is inversely proportional.
We observe that, while force increases or decreases linearly with the number of charges, distance does not. So, we do some experiments using integer powers of the distance. We see that the law is quadratic, so the distance in the denominator must be squared.
We are not happy. We vary other things. We place our charges in a glass bell jar, but we see that the force doesn’t change. The same goes for creating a vacuum or using a gas other than air. We experiment in the sun and the rain, and it makes no difference. In the end, we are certain that the electrostatic attractive force between two groups of oppositely charged particles depends uniquely on their number and their distance. That’s all.
We plot everything on a graph and make some correlations, because there’s some constant that needs to be determined to make the numbers add up. When we have finished, we put our result to the test. It works. We’ve discovered how to calculate a difficult-to-measure quantity from much simpler ones without actually having to measure it.
You might object: could we have done other experiments that would have highlighted other things that our result depends on? No. Why are you so sure? Because our prediction and the measured value match up to the seventh decimal place. I’m sure. Empirical corroboration is the final word.
With this law, we can build an algorithm that makes predictions about force, which has one essential characteristic:
If we use this algorithm to run two simulations on our system of charges under the same conditions (same charges, same distance), we will obtain the same force.
This statement seems trivial and incredibly stupid, but it isn’t.
When a calculation procedure (an algorithm) works this way, it is said to be deterministic. For nearly four centuries, the exact sciences have produced only deterministic algorithms and theories.
Whatever you can think of, no matter how complicated—quantum mechanics, general relativity, electrodynamics, thermodynamics, the design of static structures and aerospace aircraft, satellites in orbit—all have deterministic procedures at their core. A bridge stands precisely for this reason: during the design phase, we use deterministic algorithms to do simulations given certain stresses and loads, and they will predict that the bridge will always behave the same way if the stresses and loads are repeated.
Deterministic algorithms are the only ones that allow us to make “true” predictions.
The Weak Artificial Intelligence Paradigm
Now, since our company has become famous all over the world and is interested in these topics, we are contacted by a multinational company because it has a big problem. It tells us this: “We have an endless database of purchases of books from people around the world. We can make refined statistics, and we know how many books by category will be purchased next year, but they are aggregated, and we don’t know if a single person will buy a book and on which topic. We can no longer use statistics, which apply to large numbers. Can you help us?”
We put ourselves to work. For four centuries of science teaching, what works does not change. We repeat the procedure we know. Therefore, the first step is to identify the easy quantities to measure (already measured in reality because they are in the data set), the independent variables. Easy, we think. The database contains everything this multinational knows about buyers, who not only buy books, so we have to filter those characteristics relevant to our problem.
Let’s start. Is age relevant? Yes, we would say yes. We expect essays on Hegelian philosophy are not bought by three-year-old children, assuming that they could shop alone. The country of origin? Yes, we would say this too. We expect that in Europe and the USA, more books are sold than in some third-world countries, which are more worried about eating every day than reading. Okay, we’re going well. The cultural level? Certain. We expect the essays to be read more by graduates than by workers, who perhaps read more short stories. How can we evaluate the cultural level? We can use income or academic title. Optimal! The weight? Mmmh, difficult. Maybe overweight people buy more cookbooks, but we are not sure. Furthermore, we should know their heights to understand if they are overweight. However, we include it. And so on.
When we have finished, we get a gigantic list of characteristics that we believe influence the purchase of books by people. But we ask ourselves, could it be that some of these are not needed? Yes, it could be. The weight before, we don’t know. But everything’s fine; there is a statistical procedure that tell us if there is something not relevant, and we can eliminate it. Well.
Could it, however, be that there are things that are instead relevant for the result but not present? It can be. What would they be? We do not know. Do we know at least how many missing features there are? No.
However, we have to go on. We decided that those we have identified are all the independent variables on which our problem depends. We apply a neural network and measure the error on a part of the database that we left aside. And we get quite low errors in the prediction. Happiness.
Now we make different simulations. We launch the neural network again on the same data. The network uses them all, but every time chooses each instance randomly (this is how it works, really). So, while using them all, the relative order of each record in the data set changes.
There are error fluctuations; it is not always the same. Therefore, a neural networks is a not deterministic procedure.
Good to know.
We called the multinational representative to meet with him and explain the results obtained and how we did the calculation. We also expose uncertainties. But at a certain point, he asks us, “Is this the best possible result? Because we pay for that.” We have to admit that we don’t know. It could be that with other numbers or more features, we get better results, but it could be no. We go back to the office with our tails between our legs.
It happens that a few days later, by having a coffee with a friend who works in another company and who came to visit us, we learn that he has obtained a formula that allows us to combine all the numbers and make precise predictions on the data set of books. In short, a deterministic procedure. We ask him, “Are the independent variables all there?” “Yes, because I know bla, bla,” and he explains. Once we are convinced that his algorithm holds up, then we can throw away our neural network.
This example illustrates the correct approach to thinking about a problem to which we apply a predictive artificial intelligence procedure.
The AI is a fallback, and we use it only when a deterministic procedure that does the same thing is not available, which happens when the problem is not well defined or there is no explanatory theoretical model below.
Why are we talking about paradigm AI (over the deterministic paradigm)? Because:
A shift is necessary in our mental approach that allows us to live in doubt, without knowing if we have used everything we need and, above all, without knowing how close we are to the optimum theoretically obtainable within our problem. An absolute optimum that we cannot know what it is.
At the dawn of AI, the initial encouraging results made researchers think of the possibility of building intelligent devices, that is, machines that would have given an approximate response to unknown problems, as we have seen, but which would have allowed us to obtain a result regardless of the problem and the context. A true artificial intelligence. What is known as the paradigm of strong artificial intelligence or artificial general intelligence (AGI). It was seen that it was not possible.
Connectionism (neural networks) solved some historical technical problems in the 1980s that allowed the application to be successful in specific problems. So, not devices that learn in any condition, but machines that learn in very specific and delimited areas. This is the paradigm of weak artificial intelligence. The transition from the strong to the weak one is known in literature as strategic retreat, in practice, a redefinition of the objectives of the discipline.
Weak artificial intelligence constitutes a double fallback: regarding problems, as in the example of the database of books, and regarding strong artificial intelligence.
When we realize that we are unable to do something, that we come across some limitation not linked to a specific problem but structural, we have to back away and carve out our ambitions.
This is valid in any scientific or technical context. The positive aspect is that every time we encounter a limitation, we learn something. It’s often said that in life we learn from mistakes. In the technical-scientific context, we learn from limitations, from those situations in which we realize we’re unable to do or know something.
There are countless examples we could offer:
- There are mathematical functions, and therefore problems, that cannot be solved by any machine. The spectrum of tractable problems includes only those that can be computed by a Turing machine. The mathematical proof of this impossibility sheds light on the potential we have in solving problems with computing devices, including in the field of AI. We have therefore learned what kinds of problems we can tackle.
- The Godelian (metamathematical) proof of the Incompleteness Theorem (1931) forces us to accept that there are truths that cannot be proved in formal or axiomatic systems. This is a strong statement. Our attitude toward formal problems underwent a radical change before and after 1931. Similar proofs allowed us to understand essential questions about the theorematicity and truth of strings of symbols produced by axiomatic systems. In particular, there is no decision procedure for theorematicity—that is, we cannot know a priori whether a string of symbols representing a proposition can be proved or not by looking at how this string is constructed (Turing), but there is no decision procedure for the truth of these propositions either (Tarski’s theorem).
- Quantum mechanics has highlighted a structural limit of nature: the exclusion principle. There are pairs of properties of a physical system that cannot be measured simultaneously with arbitrary precision.
- The limit of the speed of light in a vacuum, that is, the fact that all observers measure the same speed of light regardless of their state of motion (as opposed to massive objects, whose measured speed depends on the state of motion of the observer), has allowed us to understand that time and space are relative, as well as having clarified that events that are simultaneous for one observer are not, in general, simultaneous for another moving with respect to him.
It is important to understand that what the IT giants do is to put more people into play who think about these things and more computational resources, perhaps also developing new procedures or refining existing ones (I would rather not trivialize), but:
From a methodological standpoint, the IT giants achievements, for stunning that they may seem, are subject to the same theoretical limitations to which we are using our modest personal computers.
What is certain is that if one day we could make the reverse passage, from the weak to the strong AI, it will be because additional criteria and additional contour conditions have been identified, which are beyond the simple error measure we do today. Some authors have made proposals in this sense.
EANNs can be considered an attempt to put one of these additional contour conditions into practice.
The Overfitting Problem
When we apply a neural network, the starting data set is processed and divided into at least two parts: the training set and the test set. The first is used to train the network, the second to evaluate the results. This mechanism is called cross-validation. The logic is to perform measurements on data that the network has never seen before to objectively assess the results.
Now, suppose we apply an identically divided data set to two different neural networks. We will obtain different errors, obviously, but let’s assume they are so close that the difference can be attributed to a simple fluctuation resulting from the order in which the data were used during training. For practical purposes, from the standpoint of the quality of the results, both should be considered equivalent. Which of the two should we choose? Half a century of practice has made the following heuristic explicit:
Between two networks equivalent regarding the test set, take the one with the highest error in the train set.
I mean, are you telling me we’re going crazy tackling unknown problems, using computers, programming, mathematics, and statistics to lower prediction errors, and then telling me we have to take the one with the highest error? Absurd.
Yes, that’s precisely what I’m saying.
The fact is, if the error gets too low on one part of the data, the network becomes too close to it. But what we gain on one side, we lose on the other. In general, a very low error on the training set will mean a much higher error on the test set. That is:
An excessive fitting to the training set implies a loss in the ability to generalize to new data, which is known as overfitting. To minimize this effect, we take high prediction errors. But we can’t assume high errors regardless. We have to choose networks that are close to the training data, close enough. But not too close.
When we evaluate a neural network, we get a number, a score, the result of several additive contributions. One is error, which we try to minimize by increasing the prediction’s fit to the data, but others are intended to distance from that fit. The relative contribution of these terms is largely arbitrary. There are no fixed rules, although some have been shown to work quite well.
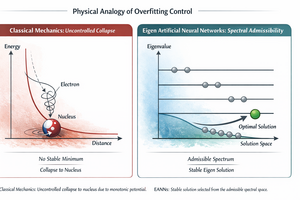
Balancing all these aspects is difficult to achieve an effective predictive system. EANNs have criteria that distance us from this excessive fit to the data, criteria that, however, arise from physical, not statistical, considerations.
The Physical Foundation of an EANN
In school, we’re taught that physical systems have a property called energy. In mechanical systems, total energy is the sum of two contributions: kinetic energy, based on how fast an object is moving, and potential energy, derived from that object’s interaction with other similar objects. Physics explains that this interaction occurs because interacting objects emanate a force field to which other objects of the same type are sensitive. In many important physical systems, the potential energy of an object, due to being immersed in a force field, depends exclusively on the relative position of that object regarding other similar objects that constitute field sources. These fields are called conservative.
When a mechanical system of this type evolves over time, an interconversion between kinetic and potential energy occurs, but not in any way. Evolution is such that at the end of the process, the total energy of the system has decreased. If we avoid getting bogged down in questions of entropy, we can roughly say that:
A process will occur spontaneously if the final state of the system has less energy than the initial state.
In the systems we’re interested in, with objects interacting via conservative fields, in the absence of external forces and impediments, the objects modify their relative distribution (and therefore their overall potential energy) to reach the configuration that ensures the minimum total energy. For conservative systems, configuration refers to the spatial location of bodies, that is, their coordinates in space.
There are some interesting discussions that we might call philosophical or epistemological. Among all the possible paths, how does a system understand in advance which one it must follow to end up in a state of lowest energy? What does it do, predict the future? Physics has discovered other minimum principles, such as the least action principle, that allow understanding questions like that. In reality, objects follow all possible paths, but the one we see is the most probable. For small objects (atoms, subatomic particles), there can be significant contributions to the probability due to different paths, but for macroscopic objects, the contribution of paths apart from the one we observe is negligible, as they are extremely unlikely.
An EANN is based on an analogy, a “physical metaphor” with atomic systems.
We know that an atom has an electric internal structure. We have protons (positive) in the center (the nucleus, which we can consider fixed) surrounded by electrons (negative) that move around it. The number of protons and electrons is equal, so the atom is electrically neutral.
Regarding its possible evolution, classical physics predicts that this system should have the electron stuck to the proton. That is, in the absence of impediments and external forces apart from the force of electrostatic attraction:
The electron should collapse onto the nucleus because this is the lowest-energy configuration.
Needless to say, this doesn’t happen; otherwise, matter would collapse upon itself, and no one would be reading this article.
Therefore, classical physics is not suited to understanding what happens inside an atom. In fact, in the early 1900s, a new theory, quantum mechanics, was created to account for these phenomena. According to this theory, an electron will be quite close to its nucleus. That is, the electron belonging to an atom in a rock on the Earth’s surface will not be at the edge of the solar system, but it will be quite close to the proton (as in the previous discussion, paths in which the electron is very far from the nucleus exist, but are unlikely). But not too close.
If an electron and a proton are at a certain distance and feel their fields, in the absence of impediments and external forces, they will approach each other, causing a decrease in the system’s energy, but up to a certain point.
Further approaches beyond the equilibrium distance are not possible, not because they entail an increase in energy, but because they constitute physical states forbidden by theory. The greatness of quantum mechanics is that these states are not imposed (as was the case with Niels Bohr’s first version in 1913, the so-called old quantum theory) but rather result naturally from the mathematical formalism, which arises from physical considerations.
The reader will probably have already grasped the analogy we mentioned earlier.
In AI procedures, we must, to avoid overfitting, be close enough to observations but not too close. In an atom, the electron is close enough to the nucleus, but not too close.
This analogy forms the starting point for the mathematical treatment of an EANN.
EANN as a Quantum System
A data set is a matrix (a grid) of numbers that contains everything known about a given problem. The columns of this grid represent all the features relevant to the problem at hand. Each row represents an instance (i.e., a particular combination of features) of the problem. Suppose the last column is the target we want to predict as a function of all the others. Formally:
What we want is to obtain a formula that relates the value of the last column to all the others when a certain arbitrary instance is given.
And that’s precisely what a neural network does.
Suppose this last target column is a physical entity that generates a conservative field. We build a model that makes predictions (good or bad) of this measured target, and suppose that the predictions generate another conservative field of “opposite sign”. Let’s also assume that these two fields generate a net field, as happens in conventional physics with charges, and that a potential energy value can be measured for this interaction. Then the physical analogy gives us a criterion for optimizing a neural network:
Try different models and lower the interaction energy, as if it were a real physical system.
What rules should I use for this? Well, not the classical physics ones, which we’ve already seen don’t work for atoms, but the rules of quantum physics. Why? Because the limitations we’ve highlighted still apply (it would take too much technical detail to fully explain why this is the case). To bring the analogy even closer to quantum mechanics, we can consider an EANN as a system composed of a particle bound to a “nucleus” by a net conservative field resulting from the predictions (the neural network model) and the observed targets.
There are significant differences between the atomic system and an EANN. The analogy is only a starting point. In an atom, we’re talking about negative electrons and positive protons attracting each other in space.
In an EANN, we’re talking about a (virtual) particle bounded by a net field resulting from the fields generated by predictions and targets.
Thus, we need to be able to lower the interaction energy (which is equivalent to bringing predictions and targets closer together) up to a certain point to avoid overfitting. There must be a limit we shouldn’t exceed, for example, because at a certain point the total energy doesn’t decrease proportionally at the same rate as the potential energy, or because the potential energy increases. An EANN is a quantum system in all respects that puts this principle into practice.
But how do I measure this interaction potential energy? Globerson et al. have proposed the minimal mutual information principle (MinMI), where mutual information (MI) is a positive statistical quantity that can be measured on data. According to these authors, when a model approaches the target, what we are doing is minimizing mutual information.
In an EANN, mutual information constitutes the system’s positive potential energy.
The mathematical definition of MI highlights how, in the case the MI is zero, the inputs and outputs of our data set are independent, and it is not possible to build a predictive system. Thus, for problems where there is a relation between inputs and targets, MI is always positive. This fact is consistent with quantum mechanics, which states that for a constrained system (i.e., one in which a potential binds the physical objects under study), a zero-point energy exists, that is, a non-null energy at the minimum of the system. If there is a relationship between the data to be predicted and all the other data in our data set, then it must be possible to minimize the energy of the system without vanishing it.
The following observation arises spontaneously: if we continue to lower the MI, are we heading straight for overfitting, or not? Yes, that’s correct, but the potential is only one part of the energy of a physical system. There is also kinetic energy. Like any physical system, an EANN is the sum of both contributions.
Initially, when the predictions are very far from the target, the energy is high. As the values between these two approaches, the kinetic and potential energies decrease up to a certain point. There is a limit beyond which further decrease is not possible, since the energy is quantized and therefore can only assume certain values:
States with energies below the minimum are forbidden by the uncertainty principle.
One might think this is an imposed limit, but that’s not the case:
Potential energy cannot be arbitrarily lowered without taking kinetic energy into account.
There’s a very precise numerical relationship between the two, called the quantum mechanical virial theorem. This constraint prevents potential energy from falling below the system’s natural values, the eigenvalues.
If the model is well-calibrated, this limit allows us to get close to the target, but not too close, thus avoiding overfitting.
If we assume the rules of quantum mechanics are valid and certain physically consistent principles are met, this behavior arises naturally from the theory.
There are many technical problems with this approach. For example, in an atom, the coordinates of the nuclei are known and only the electrons move, but in an EANN, we have no established coordinates for the field sources. However, the current theoretical development of EANNs has allowed overcoming this and other problems, making it a reliable and functional procedure.
Conclusions
EANNs are a novel methodology aimed at solving the problem of optimizing learning systems. It is based on first principles derived from quantum mechanics and therefore has a solid physical foundation.
Similar physics-based alternatives have existed for a long time, such as Boltzmann machines and Hopfield networks, and more recently, physics-informed neural networks (PINNs). However, this is the first time a method based entirely on wave mechanics has been proposed.
The theoretical model is still under development. Time will tell whether it constitutes a generally valid approach and a real alternative to established methods.
The work is pending acceptance for publication in an international journal, but a preprint is available at arXiv and Researchgate.