Integration: The Key Word in the Problem of Urban Pollution in the Next Smart City of the Future

Janusz Walczak - https://unsplash.com/photos/smoke-billows-from-the-stacks-of-smoke-stacks-SvOolOyZQPc
Deterministic Algorithms vs. Weak Artificial Intelligence Paradigm
New analytical techniques are revolutionizing virtually all areas of human knowledge. Artificial intelligence, in particular, offers an arsenal of mature and reliable methods that allow us to tackle problems that, until a few years ago, were beyond the reach of our investigative tools.
As is now well known, artificial intelligence has transformed some of these classically intractable issues into tractable ones. But we must pay a price for this increase in our analytical capacity: the inability to absolutely guarantee that the solution found is the optimal one, the best possible. This is what is called the weak artificial intelligence paradigm. We cannot avoid this sacrifice, which is the result of an inadequate definition of the problems we want to solve.
Given a problem and its constraints, we therefore move from “the solution” to “a solution.” But replacing a definite article with an indefinite one is not simply a matter of style. It implies a huge mental and conceptual leap in the way we observe the world. A true paradigm shift.
This is particularly evident in predictive AI, which addresses inference (forecasting). The power of methods like neural networks and others allows us to obtain a result even when we don’t know the problem well. AI algorithms seek patterns in the data and always offer us an answer. These solutions must then be critically analyzed to determine whether they constitute an acceptable response.
New challenges, new methods, we might say. But new compared to what? Compared to the way we have traditionally solved the world’s problems. For nearly four centuries, from Galileo to the present day, we have understood that the analytical methods we use have common characteristics, which have crystallized, within the empirical sciences, in the so-called scientific method. This analyzes issues with some criteria, such as physical laws, proposes a theory, and evaluates the validity of the reasoning by confirming the theory’s predictions with observed facts. An approach known today as hypothetical deductivism. This approach implies that all the parameters on which the problem depends have been identified. In the case of indeterminate “degrees of freedom,” unknown quantities, we obtain the “ill-defined problem” we mentioned earlier. This constitutes, to use a pun, the definition of an “ill-defined problem.”
We therefore have two different classes of problems: classical ones, which we can approach with the “scientific method paradigm,” and new, poorly defined ones, which we can treat with the “weak AI paradigm.” This is a simplistic classification, but one we will consider precise enough for a divulgative text like this.

Too complicated.
It is indeed too complicated. Not so much because of the technical difficulties of the questions (the mathematical methods of analysis are essentially the same for both classes), but because we must change our mental approach depending on the issue we are facing.
So, we might be tempted to reason this way: since poorly defined problems are more complex than classical ones, and since new techniques allow us to tackle the more complex ones, let’s use them in every area and for every question. Classical problems will be implicitly considered in some way. This would allow us to have a unique mindset, avoiding having to change our way of reasoning every time. Is this correct or not?
Not in general. And this is the main source of the drawbacks in the uncritical use of AI techniques. Paradoxical episodes are now recurring, such as lawyers being disbarred for proposing nonexistent court rulings generated by some chatbot. These things happen because, since these techniques are so recent, we are not yet generally capable of implementing the paradigm shift, that leap in mental approach we mentioned earlier, whenever necessary. In practice, we evaluate the machines’ responses with the “classic” criteria we were taught in school, and we implicitly assume that the machine has followed the same path we did, employing deterministic causal reasoning. But chatbots do not follow deterministic criteria but probabilistic ones, and in the absence of information for a precise response, they generate what they were designed to do: the most probable response. We humans certainly apply some screening criteria. But if anything, we very poorly evaluate the overall coherence of a response, which, as is evident from the increasingly frequent episodes, proves insufficient.
The mental approach we apply to the responses generated by chatbots isn’t a matter of life and death, of course. We could call it a matter of “convenience,” which allows us to make the most of powerful tools. If we sometimes relax and overlook the critical evaluation of the response, well, never mind, worse things have happened.
Right. But there are areas where we can’t afford the luxury of operating this way. If an engineer designs a bridge, he needs to be certain that if the loads, the distribution of stresses in the structure, and the environmental conditions are repeated, the bridge will always behave the same way. In this case, “an answer” isn’t enough; we need “the answer.” A bridge structure resulting from an approximate solution doesn’t work. The engineer has no choice; he’s forced to think about his structural calculations the “old fashioned way” and apply classic deterministic techniques that guarantee “the result.”
It’s therefore useful to be aware of the types of problems that can be addressed with all these techniques to apply the most appropriate tool each time. The guiding criterion for this choice can be stated as: maximizing the probability of obtaining the best result given certain a priori constraints. Measuring this probability for making this choice is beyond the scope of these notes.
This implies a preference criterion between classical and AI techniques, with the former being preferable whenever possible, as they are the only ones that guarantee a certain, reproducible (deterministic), and unique (not always) answer. This turns AI techniques, in a certain sense, into a “fallback” to be used when, faced with an ill-defined problem, we have no other way to generate a solution and where an approximate solution is acceptable and better than no solution at all. Assuming we make the necessary paradigm shift to be able to critically evaluate the result obtained.
This entire preamble clarifies an important aspect of the mathematical techniques we apply to solve problems. On the one hand, we always want to use deterministic techniques, but on the other, the computing power available today allows us to tackle ill-defined problems that require approximate techniques. Both are complementary sides of the same coin, which represents the totality of all possible problems. Remaining exclusively on one side today means limiting the power of our ability to act.
Since both types of techniques are necessary, let’s return to the key word explicitly stated in the title: integration. The integration of AI with deterministic techniques represents a formidable combination in addressing the challenges of today’s world and extends the power of the tools at our disposal in a way that was unthinkable just a few years ago.
The following considerations outline a course of action in a specific area of predictive AI. Generative AI (chatbots, LLM) is outside the scope of this discussion, except for serving as a cognitive interface, that is, an intermediate layer that allows predictive AI models to be interrogated and responses to be obtained in natural language.
An Example of Integration: Prediction of Critical Pollution Episodes in Urban Areas
Urban pollution is an ideal case study to illustrate the power of integrating both types of techniques we’re discussing. We often see vehicle traffic restrictions in cities due to critical pollution episodes or when air concentrations of some chemical indicator exceed permitted limits. Predicting these episodes in advance is certainly of interest to decision makers, who can implement policies to contain critical phenomena more effectively.
Knowing, for example, that there is a high probability of one of these situations occurring within a set number of days can allow decisions to be made over several days, allowing actions to be spread out over time. In this way, limiting the number of vehicles from circulating each day becomes less aggressive than it would be once a critical situation has already developed, requiring a drastic reduction in pollutant concentrations as quickly as possible. Consequently, the resulting inconveniences are reduced, and the quality of life for residents is improved.
These types of problems will be overcome once internal combustion engines are replaced with electric ones. Meanwhile, critical pollution incidents will continue to occur, requiring the implementation of appropriate policies.
Naturally, to best justify any action (and this applies not only to the issue of urban pollution we are considering), it is necessary to have the most comprehensive overview possible of the issue at hand, i.e., complete information.
Let’s now define the result we wish to achieve. We can formalize it this way: construct a map of the concentration of a chemical indicator (a substance) at each point in a specific territory or area (e.g., a municipality) in the future (the next few days). The clause “at every point of a specific territory or area” is how the previously mentioned completeness of information is configured in the context we are considering.
To achieve this goal, we must define our starting point, what primary information we have, and what raw materials we can work with. In this case, these are the emissions from all sources that contribute to increasing the concentration of the chemical indicator under study.
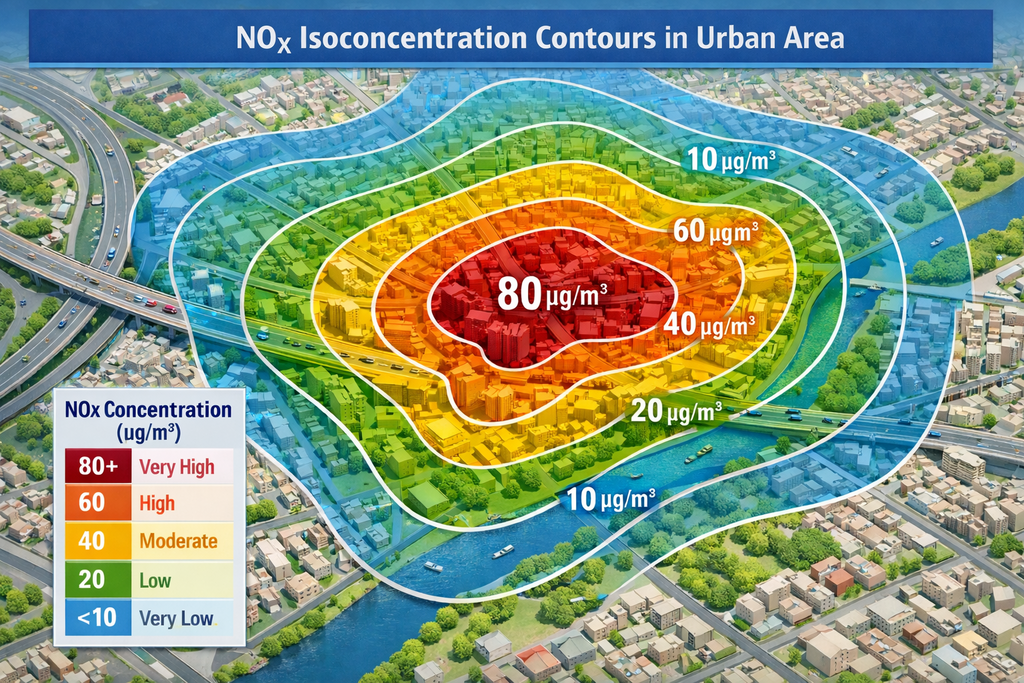
The problem is easily defined: we must find a procedure that, starting from emissions per unit of time alone, allows us to obtain the iso-concentration curves of the chemical indicator for the municipal area predicted for tomorrow. This is a complex issue, and solving it requires both deterministic and AI techniques.
Since we want to build a pollution map for the next few days, it seems natural to start by building the pollution map for today. This approach has the advantage of allowing us to use only familiar data, as we’ll see below, without having to resort to prediction techniques. Therefore, this first objective (OBJECTIVE A) concerns the deterministic part of the integration of classical and AI techniques. We’ll call OBJECTIVE B the one relating to temporal prediction issues.
As in any deterministic problem, OBJECTIVE A requires defining all the parameters that may influence our outcome. These parameters can be grouped into two categories: the quantity of pollutant emitted per unit of time, linked to the emission sources, and how this pollutant spreads across the territory once released, linked to meteorological conditions.
Let’s start by defining the sources. Typically, the winter period is considered in simulations, as it is worse in terms of pollution due to the contribution of heating. Broadly speaking, we have three types of sources:
- industrial sources (point sources). Production facilities must declare the quantity of pollutants emitted per unit of time. In addition, other necessary data is required, such as the number and height of chimneys, etc.;
- heating (areas). It is difficult to obtain a complete inventory of the number and type of boilers in the municipality. To overcome this difficulty, individual city blocks are considered to emit a quantity of pollutants proportional to their area, based on an appropriate emission coefficient. Tables containing these coefficients are widely used and allow heating emissions to be modeled with good accuracy;
- traffic (linear). Municipalities use software that divides the road network into individual linear sections, allowing them to calculate traffic flows and run simulations to understand how these flows evolve when the road network is modified. One of the results of the simulations is the number of vehicles per unit of time on each linear section. Appropriate emission coefficients per vehicle and meter allow the total emissions for each section of the network to be calculated. European and national public bodies periodically release updated tables of emission coefficients for the various categories of vehicles in circulation.
Therefore, the total emissions from each type of source are known.
The second part of OBJECTIVE A concerns how these emissions spread through the atmosphere, which depends on meteorological conditions (degree of turbulence, wind, etc.). This too is a solved problem: since the 1970s, many authors have studied this problem and proposed equations that allow for the deterministic calculation of the shape of plumes (in emissions from industrial sources), the diffusion of the pollutant based on wind speed and other weather conditions, etc. These widely used and reliable models consider only steady-state conditions, meaning continuous emissions and weather conditions do not change over time.
By putting all these elements together, we know, based on emissions and atmospheric conditions, what the concentration of pollutant will be on the ground at a certain distance from the sources. This calculation can be performed for any point within the municipal territory, allowing us to construct our pollutant concentration map valid for today.
Note that this is a deterministic calculation: as with the bridge example mentioned above, if we repeat the calculation with the same sources and the same weather conditions, we will obtain the same map for the chemical indicator under study.
We are in a position to address OBJECTIVE B: obtain the same map, but for tomorrow. We need to consider some data available.
First, the sources: we can assume that tomorrow’s emissions will not be different from today’s. We consider this to be a known fact. For atmospheric conditions, we can use tomorrow’s weather forecast, which is also a known fact and, given the limited time frame we are considering (one day), also very reliable.
What else is needed to predict tomorrow’s pollutant concentration? We need a historical series, as long as possible, of measured concentrations and corresponding weather data. An algorithm that learns from the data, such as a neural network, allows us to obtain an estimate of this value.
However, there is a problem in achieving OBJECTIVE B. Measurement capacity is limited, and historical series are only available for a very few points. Typically, municipalities have several fixed monitoring stations and some mobile equipment, and data is only available at the locations where the sensors are located. Therefore, our predictions are only available for a few specific coordinates.
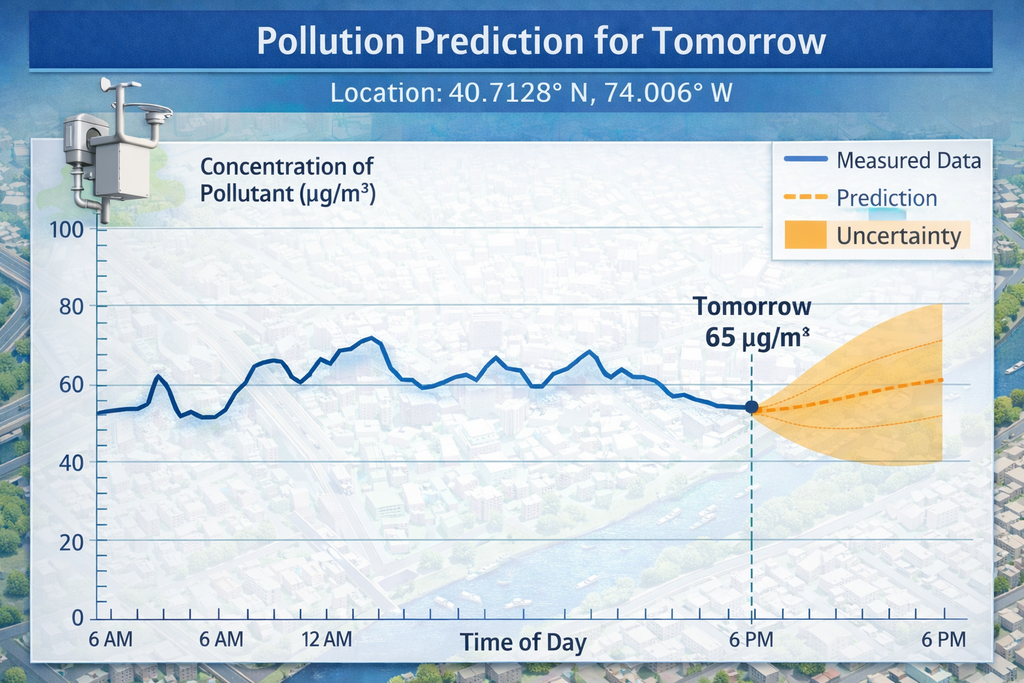
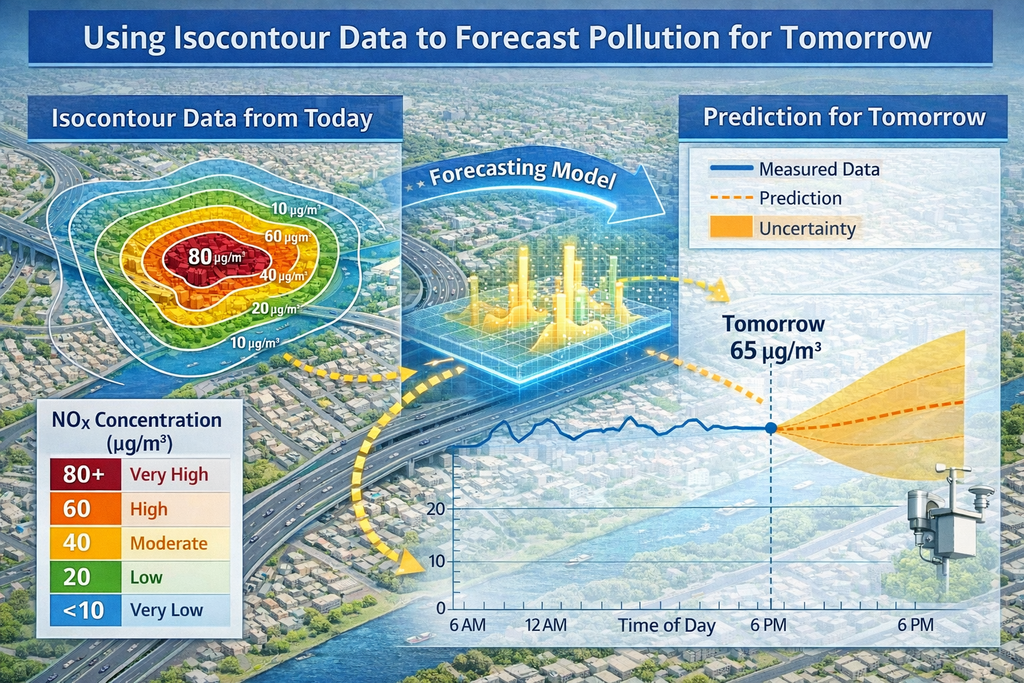
However, OBJECTIVE A has provided us with a map of pollutant concentrations across the entire territory, so we know the ratio of the indicator’s concentration, valid for today, between two arbitrary points. If we combine these two information sources, we can estimate tomorrow’s predicted concentrations at certain points with those at all others based on the ratios provided by the steady-state situation (OBJECTIVE A).
Of course, some work is required. We’ll need to choose the pre-calculated steady-state situation that best fits tomorrow’s forecasted conditions, considering wind direction and speed and other weather or emissions conditions compatible with the prediction we want to make. This is not difficult, provided we have sufficient data and an adequate number of “all-purpose” steady-state conditions, as provided by the results of OBJECTIVE A.
It is possible to build a continuous system that acquires data measured by monitoring stations and forecasted weather conditions, for example, from meteorological networks, and implement a procedure that provides real-time future pollution predictions.
Conclusion
The methodology described is an example of the predictive power available when deterministic techniques and AI algorithms are combined. The same integration principle can be applied to other problems with the aim of characterizing them and obtaining comprehensive knowledge. Our ability to address complex challenges, derived from this knowledge, represents the near future of modeling applied to real-world problems.